mlvajra
"A weapon to save Data Scientist from frustration "
mlvajra's goal is to have a Best practices to Deploy Machine learning in all environments in one place
mlvajra
-
Week supervision to generate a labeled dataset from unlabled dataset (using domain knowledge)
-
Active learning strategies
- week supervision (Snorkel)
Easy deployment
- Edge Deployment (in Big data Environement)
- Deploy in Docker containers as Mircoservices
Monitoring
- Have a strategy to monitor the performance the model in production environment
Experiment Traccking
- Have Experiment tracker with your production data and design your pipeline in such a way to replace the old model with the best model tracked with your Experiment results
Reference:
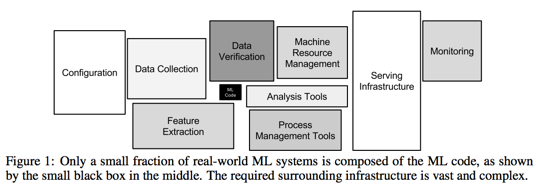
https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems